

Nmap/Spidering Library
Contents
Spidering Library
The spidering library will provide a complete implementation of a web crawler. The information found by a crawling a web server is useful to a variety of NSE HTTP scripts that perform tasks ranging from information gathering to web vulnerability exploitation. Creating this library will also improve the code quality of existing and future scripts by separating the logic of the web crawler from the script.
Features
- Supports multiple scripts running.
- Supports settings to control the crawling behavior.
- Fast
- Flexible
- Uses the http cache system from http.lua
- Support cookies and redirects
Options/Settings
Supported settings
- httpspider.allowRemoteURI Turn on to allow spider to crawl outside the parent website to remote sites. Default value: false
- httpspider.cachePageContent Turn on to write cache files containing all the crawled page's content. Default value: true
- httpspider.subcrawlerNum Sets the number of subcrawlers to use. Default: 3
- httpspider.pathBlacklist Table of paths that are blacklisted. Default: nil
- httpspider.ignoreParams If set, it removes the query parameters from URIs and process them without arguments. Useful when crawling forums or similar software that has a lot of links pointing to the same script but changing arguments. Default: false
- httpspider.showBinaries Shows binaries in the list of visited URIs. Otherwise binaries are not shown because they were not parsed by the crawler. Default: false
- httpspider.uriBlacklist Table of absolute URIs that are blacklisted. Default: nil
- httpspider.timeLimit Time limit before killing the crawler. Default: According to Nmap's timing template. Use 0 for unlimited time.
- httpspider.statsInterval Time limit before reporting stats in debug mode. Default: 10
- httpspider.cookies Cookie string to be appended with every request. Default: nil
- httpspider.ignore404 Ignores 404 pages extracting links from them.
- httpspider.path Basepath for the web crawler. Default: "/"
Optimizing the web crawler
To exclude a list of URIs you may set the argument httpspider.uriBlacklist
If you want to ignore the parameters in scripts, you may set the argument httpspider.ignoreParams. This is useful when crawling webservers with software like forums.
To include binary files in the list returned by the crawler, you use httpspider.showBinaries
If you are dealing with applications that manage session through cookies. You may login with a web browser to obtain your session cookie and set it with httpspider.cookies.
TODO
- Add proxy support - Connections through a proxy. Maybe this should be handled by the http library.
- Limit by crawling depth - Number of levels to crawl. Ex. A crawl depth of 3 will go as far as /a/b/c/ but won't visit /a/b/c/d/(Optional)
- Additional whitelist/blacklist for IP,PORT,VHOST,Subdomains
- Improve cookie handling - (Update cookies between requests)
Design
Algorithm
The spidering library uses the following algorithm:
- Main Thread (MT) receives starting URI and parses it to find new URIs.
- If the document is empty, return.
- If not:
- -MT creates N number of NSE threads.
- -MT sleeps until crawlers are done.
- PHASE 3
- Each crawler remove URIs from the "unvisited" queue.
- It parses the document to find new URIs.
- For every URI found it checks if it passes all the filters: URI blacklist, extension blacklist, remote hosts, etc.
- If it passes -> Add it to the "not visited" queue after converting it to its absolute form.
- After a crawler is done with a page it requests a new URI from the "not visited" queue and starts from phase 3 until the "unvisited" queue is empty..
Function list
- function crawl(host, port)
--Crawls given URL until it follows all discovered URIs --Several options can alter the behavior of the crawler, please --take a look at the documentation closely. --@param host Host table --@param port Port table
- local init_registry() -
--Initializes registry keys to hold the visited list --It uses the key [LIB_NAME]["visited"] to store a list of pages that have been visited.
- local init_crawler():
--Initializes web crawling using the given settings. --This funcion extracts the initial set of links and --create the subcrawlers. --@param uri URI string --@param settings Options table
- local init_subcrawler():
-- --Initializes a subcrawler --A subcrawler will fetch an URI from the queue and extract new URIs, filter and add them to the queue. --The thread will quit if the allowed running time has been exceeded. --@param Host table --@param Port table
- local add_visited_uri(uri, page_obj):
--Adds uri to the Visited List page table stored in the registry --URIs in this list have already been crawled. --@param uri URI --@param page_obj Page Object
- local add_unvisited_uri(uri):
--Adds URI to a list of URIs to be crawled stored in the registry --We use a local list to check if item is already in queue to obtain constant time. --@param uri URI
- get_href_links:
--Parses the href attribute of the <a> tags inside the body --@param body HTML Body --@return Table of href links found in document
- get_src_links:
--Parses the src attribute of the <script> tags inside the document's body --@param body HTML body --@return Table of JS links found
- get_form_links:
--Parses the action attribute of the <form> tags inside the document's body --@param body HTML body --@return Table of links found
- get_sitemap:
--Returns a table of URIs found in the web server --@return Table of URIs found
- is_absolute_url:
--Checks if URL is an absolute address --@return True if "http://"/"https://" is found
- is_link_malformed - Syntax check for links, useful to detect malformed tags
--Checks if link is malformed. --This function looks for: --*Links that are too long --*Links containing html code --*Links with mailto tags --@param url URL String --@return True if link seems malformed
- uri_filter(host, uri) - Checks if rules allow a link to be added to list of pages to be crawled
--This is the main URI filter. We use this function to check a given URI agaisnt a set of filters --defined by the crawler options. --It supports the following options/filters> --* allowRemoteUri - Allows remote servers to be crawled --* file extension --@param uri URI --@return true if the crawler is allowed to visit the given URI
- is_uri_local:
--Checks if link is local. --@param url_parts --@param host --@return True if link is local
- is_link_anchored:
--Checks if link is anchored () --Example: "#linkPointingInsideOfDocument" --@param url URL String --@return True if url is an anchored link
- report_stats:
--Initializes registry keys to hold the visited list --It uses the key [LIB_NAME]["visited"] to store a list of pages that have --been parsed already. local function init_registry()
- get_timeout_limit:
--Returns the amount of time before the crawler should quit --It is based on Nmap's timing values -T4 or the OPT_TIMELIT if set --@return Time limit before quitting crawling
- has_crawler_timedout:
--Checks if the crawler has been running longer than the timelimit --If it has, it exits local function has_crawler_timedout()
Usage
I've been written a few scripts to demonstrate its usage:
http-phpselfxss-scan: Crawls a web server looking for PHP files vulnerable to PHP_SELF cross site scripting vulnerabilities. (nmap-exp/calderon/scripts/http-phpselfxss-scan.nse)
httpspider.crawl(host, port, OPT_PATH)
local uris = httpspider.get_sitemap()
for _, uri in pairs(uris) do
local extension = httpspider.get_uri_extension(uri)
if extension == ".php" then
stdnse.print_debug(2, "%s: PHP file found -> %s", SCRIPT_NAME, uri)
if launch_probe(host, port, uri) then
output[ #output + 1 ] = string.format("%s", uri)
end
end
end
http-sitemap: Crawls a web server and returns a list of all the files found. (nmap-exp/calderon/scripts/http-sitemap.nse)
httpspider.crawl(host, port, basepath)
local uris = httpspider.get_sitemap()
for _, uri in pairs(uris) do
results[#results+1] = uri
end
http-email-harvest: http-email-harvest returns a list of email accounts found in the body text of all URIs found in a web server. (nmap-exp/calderon/scripts/http-email-harvest.nse)
httpspider.crawl(host, port, basepath)
local uris = httpspider.get_sitemap()
for _, uri in pairs(uris) do
local page = http.get(host, port, uri)
local emails = find_emails(page.body)
for _, email in pairs(emails) do
if emails_found[email] == nil then
emails_found[email] = true
valid_emails[#valid_emails+1] = email
end
end
end
Registry entries
We store some keys in the registry to coordinate different scripts when running at the same time. After crawling the web server once, the library saves the results in the registry to return this sitemap to the other scripts.
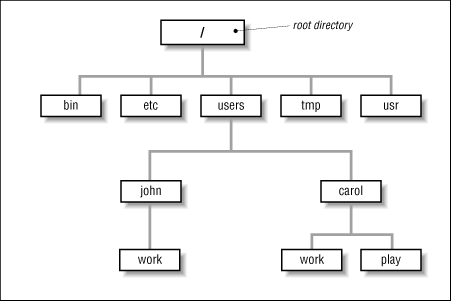
Future additions: We will use a tree representation for the data collected similar to: http://docstore.mik.ua/orelly/unix/lrnunix/figs/lu0301.gif
{kind=link}
Scripts depending on this library
Sitemap dump
Crawls web server and display a sitemap of all the files found. This script is useful to determine all the possible file-targets/attack-surface when auditing web applications.
Email harvester
Harvets email accounts from web applications.
XSS finder
Finds cross site scripting vulnerabilities in web applications. The script will crawl a web server and test every parameter of every page for cross site scripting by matching responses.
Improved SQLi finder
Finds SQL Injection vulnerabilities in web applications. [Improved version of our SQLi finder]
Redirect finder
A script to find redirection vulnerabilities that could be used for phishing attacks. Detects url patterns in arguments to find files where insecure redirections take place.
Backup finder
Finds backup files uploaded or left behind by mistake in web servers.
RFI finder
A script to find Remote File Inclusion vulnerabilities. The script will crawl a webserver looking for files taking arguments that look like filenames and urls and it will try to exploit remote file inclusion vulnerabilities by sending a url with our own file and checking the server's response.
TODO
I will try to use this wikipage to keep you guys posted on my progress regarding this library.
- Write test cases for the web crawler.
- When spoofing the user agent you may reveal additional hidden paths. We need to include this in our spider.